Hello everyone, so in this blog, I will be talking about building a transformer from scratch. This will be a long blog so I will be splitting this to a couple of parts.
Before diving into this, let’s understand a few pointers that I would like to explain in detail :
Recurrent Neural Network Disadvantages:
Here is a recurrent neural network where X’s represent the inputs, O’s represent the outputs, H’s represent the hidden states, and Y represents the training label. Recurrent neural networks used to be the state-of-the-art for sequence-to-sequence modeling, where sequences could be an ordered set of tokens, such as a set of words forming a sentence. These recurrent neural networks were, in many natural language processing applications, the state-of-the-art for sequence-to-sequence tasks. However, they suffer from two main disadvantages.
The first is that they are slow; we need to feed these inputs one at a time to generate the outputs sequentially. Additionally, their training algorithm is slow as well. We use a truncated version of backpropagation to train them, known as truncated backpropagation through time.
Perhaps a more pressing issue is that the vectors generated for every word in the case of a word language model may not truly represent the context of the word itself. After all, the context of a word depends on the words that come before and after it. However, it is clear that from a recurrent neural network perspective and architecture, we only receive signals from the words that come immediately before it. Even bidirectional recurrent neural networks suffer from this issue, as they only consider the left-to-right and right-to-left contexts separately and concatenate them. Thus, there might be some true meaning lost when generating these vectors for every word. This brings us to our next point, motivation for self-attention.
Motivation for Self Attention:
Self-attention mechanisms provides a better solution to these challenges that I mentioned above by allowing models to weigh the importance of different input tokens when generating an output representation. Also, self-attention mechanisms can capture global dependencies in parallel, enabling more efficient processing of long-range dependencies. This is achieved by computing attention scores between all pairs of input tokens, allowing the model to focus on relevant information while disregarding irrelevant context.
Since, self-attention is inherently parallelizable, it becomes computationally efficient compared to sequential models like RNNs. This parallelization enables self-attention mechanisms to scale effectively to longer sequences, making them suitable for various natural language processing tasks where capturing contextual information across the entire input sequence is crucial.
Overall, the motivation for self-attention lies in its ability to address the limitations of traditional sequential and convolutional architectures by efficiently capturing long-range dependencies and contextual information in a parallelizable manner.
Transformers Overview :
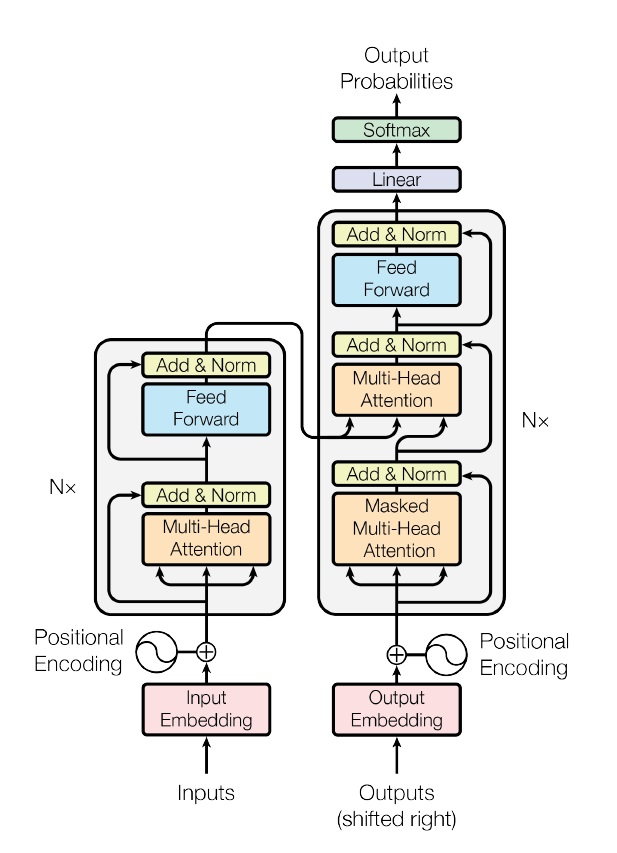
To understand stuff better, let’s look at an illustration or try to solve it ourselves, where we translate an English sentence into Kannada, a language from Karnataka, India.
Let’s say, we input the sentence “my name is prathamesh” into the encoding section of the Transformer neural network architecture. This process generates four vectors, one for each word. Although technically these vectors correspond to word pieces or sub-words, for simplicity’s sake, let’s refer to them as word-level representations.
Subsequently, these vectors are simultaneously fed into the decoder architecture. Beginning with a simple start token, the decoder utilizes these vectors to produce the translation. For instance, “my” translates to “ನನ್ನ” (pronounced “Nana” meaning “my” in Kannada), “name” translates to “ಹೆಸರು” (pronounced “hesaru” meaning “name” in Kannada), and so forth.
Transformers exhibit remarkable versatility beyond translation tasks; they can tackle various sequence-to-sequence endeavors. However, our focus lies predominantly on the encoder component.
Delving deeper into the encoder process, let’s examine the four input words: “my name is prathamesh.” After incorporating positional encoding, these words are transformed into yellow vectors, typically comprising 512 dimensions each, as elucidated in the research paper. These vectors undergo further processing within the encoder, yielding another set of vectors.
The crux of enhancing vector quality and contextual awareness lies in the attention mechanism, particularly the multi-headed attention component.
To comprehend the intricacies of this mechanism, we’ll delve into code implementation and mathematical principles underlying its functionality.
One noteworthy aspect of the Transformer architecture is its adeptness at overcoming the shortcomings of recurrent neural networks (RNNs), namely, slow training due to sequential processing. By enabling parallel data processing, modern GPUs can be leveraged efficiently. Additionally, the built-in attention mechanism ensures the generation of higher-quality, context-aware vectors.
In summary, Transformers represent a groundbreaking advancement in neural network architecture, offering unparalleled capabilities in capturing contextual nuances and facilitating seamless parallel processing.
Self Attention in Transformers :
Now, let us explore the attention mechanism further, focusing on the multi-headed attention component within the Transformer architecture. While the diagram from the main paper may appear perplexing, I’ll break it down for clarity. Essentially, each word inputted into our Transformer is associated with three vectors:
-
Query Vector: This vector signifies what information I’m seeking or what aspect of the input I’m interested in. For example: Suppose you’re planning a trip to India and want to explore its yummy cuisine. Your query vector would include your interest in Indian food, Right?. It might include keywords like “spices,” “curries,” “street food,” or “regional dishes.”
-
Key Vector: The key vector determines what information the word can provide or its relevance to other words in the sequence. Continuing to my previous example, the key vector for each region would assess its relevance to your culinary exploration. For instance, regions like Punjab, known for its rich and flavorful dishes like butter chicken and sarson ka saag or South Indian states like Karnataka or Kerala for instance are renowned for its coconut-based curries and seafood delicacies, would have high relevance scores. Meanwhile, regions less known for their cuisine, like remote mountainous areas, might have lower relevance scores.
-
Value Vector: Representing the actual content or meaning offered by the word. Again, for Punjab, the value vector would include details about traditional Punjabi dishes, cooking techniques, and cultural influences on the cuisine. Similarly, for Kerala and Karnataka, the value vector would encode information about the use of coconut milk, spices like curry leaves and mustard seeds, and the influence of coastal flavors on the cuisine
Together, these vectors enable the Transformer to dynamically focus on relevant parts of the input sequence while generating output representations.
Code with Explaination :
Exciting now eh? Make sure to understand everything above and proceed hehe. Feel free to reach out to me if you have any questions. Here is the github repository link for the below code : Github . So, Moving on with the code :
Self Attention Math
$$ \text{self attention} = softmax\bigg(\frac{Q.K^T}{\sqrt{d_k}}+M\bigg) $$
$$ \text{new V} = \text{self attention}.V $$
Softmax :
$$ \text{softmax} = \frac{e^{x_i}}{\sum_j e^x_j} $$
#PS: Code is directly exported from my google colab notebook.import numpy as npimport math
L, d_k, d_v = 4, 8, 8q = np.random.randn(L, d_k)k = np.random.randn(L, d_k)v = np.random.randn(L, d_v)
print("Q\n", q)print("K\n", k)print("V\n", v)
np.matmul(q, k.T)
# Why we need sqrt(d_k) in denominatorq.var(), k.var(), np.matmul(q, k.T).var()
scaled = np.matmul(q, k.T) / math.sqrt(d_k)q.var(), k.var(), scaled.var()
"""Notice the reduction in variance of the product"""
scaled
"""## Masking
- This is to ensure words don't get context from words generated in the future.- Not required in the encoders, but required int he decoders"""
mask = np.tril(np.ones( (L, L) ))mask
mask[mask == 0] = -np.inftymask[mask == 1] = 0
mask
scaled + mask
#---------------------------------------------------------
def softmax(x): return (np.exp(x).T / np.sum(np.exp(x), axis=-1)).T
attention = softmax(scaled + mask)
attention
new_v = np.matmul(attention, v)new_v
v
"""# Function"""
def softmax(x): return (np.exp(x).T / np.sum(np.exp(x), axis=-1)).T
def scaled_dot_product_attention(q, k, v, mask=None): d_k = q.shape[-1] scaled = np.matmul(q, k.T) / math.sqrt(d_k) if mask is not None: scaled = scaled + mask attention = softmax(scaled) out = np.matmul(attention, v) return out, attention
values, attention = scaled_dot_product_attention(q, k, v, mask=mask)print("Q\n", q)print("K\n", k)print("V\n", v)print("New V\n", values)print("Attention\n", attention)Explaination : In this notebook, we’re understood about the implementation of a Transformer model using Numpy. In this Colab notebook, we implement a Transformer using Numpy. We initialize query, key, and value vectors randomly. Each vector has a size of eight, and the sequence length LL is set to four for the sentence “my name is Prathamesh”. Self-attention is used to create an attention matrix where each word looks at every other word to determine focus. Scaling is applied to stabilize values.
Masking is essential in the decoder to prevent future word influence. We create a triangular mask to simulate this. After applying softmax, attention focuses only on preceding words. Multi-headed attention improves context comprehension, stacking results for better representation.
Finally, we encapsulate this logic into a function for both encoder and decoder use. This function handles masking and computes attention matrices efficiently.
Multi-Head Attention Implementation:
class MultiheadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiheadAttention, self).__init__() assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model self.num_heads = num_heads self.head_dim = d_model // num_heads
# Linear layers for query, key, and value projections self.query_linear = nn.Linear(d_model, d_model) self.key_linear = nn.Linear(d_model, d_model) self.value_linear = nn.Linear(d_model, d_model)
# Final linear layer for output self.output_linear = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None): batch_size = query.size(0)
# Project inputs to query, key, and value Q = self.query_linear(query) K = self.key_linear(key) V = self.value_linear(value)
# Split the projected vectors into multiple heads Q = Q.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) K = K.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) V = V.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# Calculate attention scores scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
# Apply mask (if provided) if mask is not None: scores = scores.masked_fill(mask == 0, float('-inf'))
# Apply softmax to get attention weights attention_weights = F.softmax(scores, dim=-1)
# Apply dropout attention_weights = F.dropout(attention_weights, p=0.1)
# Apply attention weights to the value vectors attention_output = torch.matmul(attention_weights, V)
# Concatenate attention outputs from multiple heads attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# Apply final linear layer output = self.output_linear(attention_output)
return output, attention_weightsThe multi-head attention mechanism is an important component of the Transformer architecture. It also allows the model to jointly attend to information from different representation subspaces at different positions which enables it to capture diverse patterns within the input sequence effectively. The Multi-Head Attention class takes in query, key, and value tensors, projects them into multiple heads, computes attention scores, applies Softmax activation function to obtain attention weights, and finally produces the output by weighted summation of the value vectors. This mechanism greatly enhances the model’s ability to capture long-range dependencies and contextual information.