Introduction to Federated Learning
Federated Learning is an approach to train the machine learning models across multiple decentralized devices or servers that hold local data samples. Instead of sharing sensitive data, what each device does is - it trains a model locally and only shares the learned parameters (like gradients or weights) with a central server. This ensures data privacy and efficient model training across a distributed network.

Fun Fact: Federated Learning was first introduced by Google in 2016 to improve the predictive text on smartphones without compromising user privacy.
In today’s digital age, data privacy is more important than ever. With massive amounts of data generated daily, ensuring that personal information remains confidential is crucial. Federated Learning addresses this need by enabling collaborative model training without sharing raw data.
How Federated Learning Works
Key Components:
- Local Devices: Train the model using local data, ensuring that sensitive information remains on the device.
- Central Server: Aggregates updates without accessing local data, combining the knowledge from each device to improve the overall model.
- Communication Protocols: Ensure secure transmission of updates, preventing any leakage of sensitive information during the process.
Let’s break down the process:
Federated Learning (FL) enables collaborative model training across multiple devices while preserving data privacy. SO, let us now explore the detailed mechanics and the rationale behind each step involved in FL.
.png)
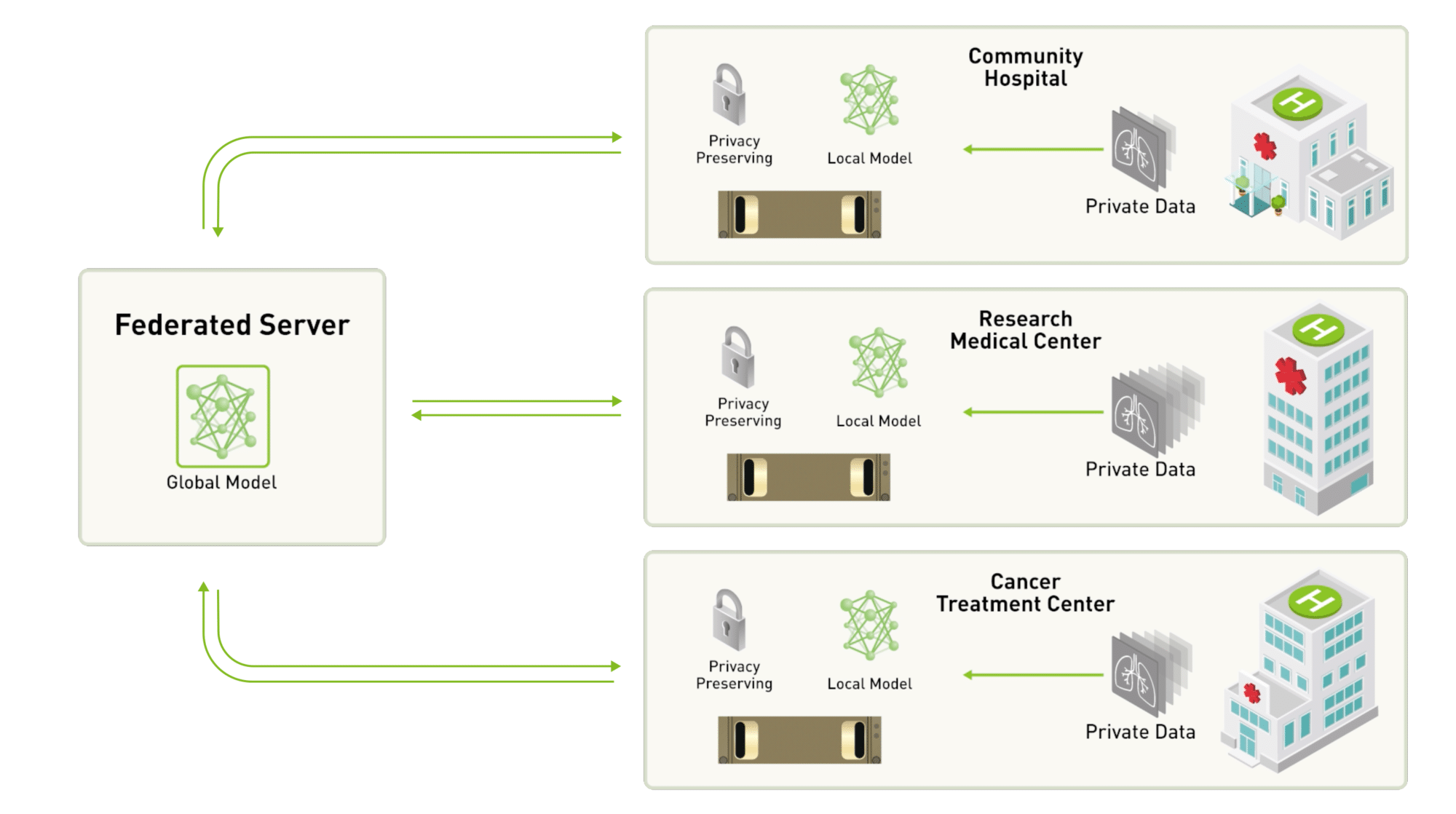
- Model Initialization: A global model is initialized on the central server. This model is typically a neural network with a defined architecture but with untrained weights.The global model is created based on the desired task. Finally in this stage, the server then distributes this model to all participating devices, ensuring each device starts with the same initial parameters.
# Initialize the global modelglobal_model = initialize_model()# Distribute the global model to all devicesfor device in devices: send_model_to_device(global_model, device)- Local Training: Each device trains the model on its local dataset. This step allows the model to learn from the data available on the device.
# Local training functiondef train_locally(model, data): # Training loop for epoch in range(local_epochs): for batch in data: # Forward pass predictions = model.forward(batch.inputs) # Compute loss loss = compute_loss(predictions, batch.labels) # Backward pass and update weights model.backward(loss) model.update_weights() return model.get_weights()
# Train model locally on each devicelocal_updates = []for device in devices: local_data = load_data(device) local_weights = train_locally(global_model, local_data) local_updates.append(local_weights)- Model Updates: Devices send their model updates (typically the gradients or weight changes) to the central server instead of the raw data. The updates contain only the changes in the model’s weights, which are much smaller in size compared to the raw data. This step ensures data privacy and reduces the risk of sensitive data exposure.
# Send local model updates to the central serverfor update in local_updates: send_update_to_server(update)- Aggregation: The central server aggregates the received updates using techniques like Federated Averaging to create an improved global model. Federated Averaging (FedAvg): This is the most common aggregation method where the server averages the weights from all the updates. Averaging the weights is effective because it combines the learning from diverse data distributions across devices, leading to a more generalized model.
# Federated Averaging functiondef federated_averaging(global_model, local_updates): num_devices = len(local_updates) new_weights = [0] * len(global_model.weights)
for update in local_updates: for i, weight in enumerate(update): new_weights[i] += weight / num_devices
global_model.set_weights(new_weights) return global_model
# Aggregate the local updates to update the global modelglobal_model = federated_averaging(global_model, local_updates)- Iteration: Steps 2-4 are repeated for multiple rounds until the model converges or reaches the desired level of accuracy. Iterative training allows the model to improve incrementally, benefiting from new data and continual learning. Each round of training and aggregation reduces the global model’s loss, gradually enhancing its performance.
# Main federated learning loopdef federated_learning(server_model, devices, num_rounds): for round in range(num_rounds): local_updates = [] for device in devices: local_model = train_locally(server_model, device.data) local_updates.append(local_model.get_weights()) server_model = federated_averaging(server_model, local_updates) return server_model
# Execute the federated learning processglobal_model = federated_learning(global_model, devices, num_rounds)Federated Averaging

This is a common algorithm that is used in Federated Learning. The updates from each device are averaged to update the global model, ensuring that each device contributes to the learning process. But why does this averaging work and what does it actually do?
- Linear Combination of Functions: The weights of a neural network can be seen as coefficients of a very high-dimensional function. By averaging the weights, we effectively create a new function that is a linear combination of the individual functions trained on each device’s data. This linear combination often captures the general trend of the data distribution better than any single model trained on local data.
- Convergence and Stability: Averaging helps in smoothing out the noise in the gradient updates. Each device’s data might have some noise, but when averaged across many devices, the noise tends to cancel out, leading to more stable and reliable updates. This is particularly important in non-IID (Independent and Identically Distributed) settings, where data distributions can vary significantly across devices.
- Generalization: By aggregating updates from multiple devices, the global model is exposed to a more diverse set of data points, which improves its ability to generalize to unseen data. This diversity helps in creating a more robust model that performs well across different data distributions.
Here’s a sample pseudo-code for Federated Averaging:
# Sample pseudo-code for Federated Averagingdef federated_averaging(global_model, local_updates): num_devices = len(local_updates) new_weights = [0] * len(global_model.weights)
for update in local_updates: for i, weight in enumerate(update.weights): new_weights[i] += weight / num_devices
global_model.set_weights(new_weights) return global_modelAdvantages of Federated Learning
Federated Learning brings several benefits to the table, making it a revolutionary approach in the field of machine learning:
- Data Privacy: Sensitive data never leaves the device, ensuring that personal information remains confidential.
- Reduced Latency: Local training minimizes delays, making the process more efficient.
- Personalized Models: Models can be customized for individual devices, improving performance and user satisfaction.
- Scalability: Federated Learning can easily scale to millions of devices, making it ideal for applications like mobile phones and IoT devices.
- Energy Efficiency: By leveraging local computation, Federated Learning can reduce the energy consumption associated with centralized data processing.
Challenges and Limitations
However, Federated Learning has a couple of challenges which is quite note-worthy. A few of them are:
- Data Heterogeneity: Variability in data quality and quantity across devices can affect the model’s performance. Different devices may have different data distributions, making it difficult to create a one-size-fits-all model.
- Communication Overhead: Frequent updates can be bandwidth-intensive, especially in environments with limited connectivity. Ensuring efficient communication protocols is essential to mitigate this issue.
- Security Risks: Potential vulnerabilities in the aggregation process can pose security risks. Ensuring secure and robust aggregation methods is crucial to prevent malicious attacks.
- Device Resource Constraints: Limited computational and storage resources on devices can hinder the training process. Optimizing the training process to accommodate these constraints is necessary.
Applications of Federated Learning
Federated Learning is making waves in various industries, transforming how data-driven decisions are made:
- Healthcare: Enhancing diagnostic models without compromising patient data. For instance, hospitals can collaboratively train models to detect diseases like cancer without sharing sensitive patient records.
- Finance: Improving fraud detection while keeping financial data secure. Banks can collaborate to develop better fraud detection algorithms without exposing customer data.
- IoT: Optimizing smart home devices through collective learning. Smart devices can improve their performance by learning from each other without sharing user data.
- Telecommunications: Enhancing network optimization by analyzing user behavior patterns. Telecom companies can improve network quality by understanding usage patterns without accessing individual user data.
- Autonomous Vehicles: Improving safety features through collaborative learning. Autonomous vehicles can share insights to enhance their decision-making capabilities without sharing raw data.
Future of Federated Learning
The future of Federated Learning is bright and promising. As technology advances, FL could revolutionize industries by ensuring privacy and efficiency in AI applications.
- Enhanced Privacy Mechanisms: Future developments could focus on improving privacy mechanisms, making Federated Learning even more secure.
- Better Communication Protocols: Innovations in communication protocols could reduce the bandwidth required for model updates, making the process more efficient.
- Integration with Edge Computing: Combining Federated Learning with edge computing could further enhance data privacy and reduce latency.
- Broader Industry Adoption: As more industries recognize the benefits of Federated Learning, its adoption is likely to increase, leading to more robust and secure AI applications.

Conclusion
Federated Learning is a game-changer in the world of AI, offering a perfect blend of privacy and efficiency. As more industries adopt this technology, we’re likely to see a significant impact on how data-driven decisions are made. From healthcare to finance to IoT, the potential applications are vast and varied.
Next Steps and Resources
- An amazing Github repo with super cool resources : Federated Learning.
- Google Cloud Tech : What is Federated Learning
- Federated Learning : Machine Learning on Decentralized Data (Google I/O’19)
- Federated Learning at Scale, EPFL
- Go through these resources throughly and ofc,
BUILDfolks!